El patrón CQRS
En este artículo voy a hablar sobre un patrón de comportamiento que considero casi siempre en el diseño de una arquitectura, el patrón CQRS.
No creo que sea siempre el más adecuado, pero en la mayoría de los casos puede ayudar a ordenar y estructurar el comportamiento de una manera clara y legible, valores a tener en cuenta cuando estamos escribiendo código.
¿Qué es esto de CQRS?
En su manera más básica, (Command Query Responsibility Segregation) es un patrón de comportamiento de arquitectura que básicamente divide el flujo de nuestra aplicación en dos, los comandos (commands) y las consultas (querys). Los commands modifican el dominio mientras que las querys solo leen.
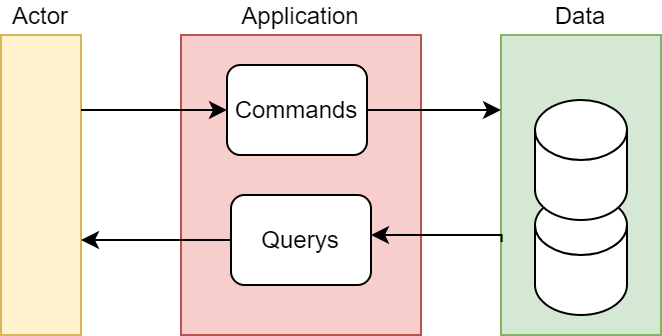
El típico caso de un CRUD, solo la lectura (Read) sería una query, y las demás (Create, Update y Delete) commands.
¿Qué nos aporta?
A simple vista esto parece complicar más las cosas que facilitarlas, ¿verdad?, bueno como todo en esta vida depende. Evidentemente en una aplicación pequeña no tendría mucho sentido la división, pero si pretendemos crear algo con una escalabilidad real, debemos plantearnos el crecimiento del sistema, tanto horizontal como verticalmente.
CQRS nos permite de buenas a primeras crear un crecimiento asimétrico de músculo de la aplicación, os pongo un ejemplo, cuando buscáis en Amazon ¿cuántas cosas miráis y cuantas compráis?, es decir, ¿cuántas querys hacéis y cuantos commands? Seguramente muchísimas más consultas que actualizaciones, y eso multiplicado por N usuarios es un problema de escalabilidad. El patrón nos permite en un sistema distribuido dividir las responsabilidades de consulta de las demás, pudiendo dotar a estas de más músculo según lo necesitemos, de una manera sencilla y ordenada.
Pero bueno, esta visión está bien si estuviésemos todo el día programando amazon’s, que no creo que sea el caso… Lo que a mí personalmente me aporta en cualquier proyecto (independientemente del tamaño) es el orden a medida que crece el caos.
Todos hemos visto repositorios colosales donde agregar una nueva funcionalidad o una modificación implica modificar un archivo con una cantidad mareante de líneas que van dejando la mantenibilidad y la estructura por los suelos.
CQRS estructura estas funcionalidades y las articula de una manera casi melódica. ¿Deseas modificar algo? Pues te diriges a la Query/Command en cuestión y la modificas, todo en un solo sitio, y todo relativamente comprimido. ¿Te han encargado una nueva funcionalidad? No pasa nada, no hay que tocar un repositorio de 5 MB con una concentración del 300% para no romper nada, simplemente creas la nueva funcionalidad agregando una Query/Command y listo, a lo mucho no funcionara tu trabajo y puedes toquetearlo hasta hacerlo funcionar sin peligro.
Desde luego no es oro todo lo que reluce, CQRS tiene sus problemas también, implementarlo en un sistema distribuido pude ser una labor bastante grande. Desde luego un esfuerzo que se ha de considerar cuidadosamente en el diseño de la arquitectura. Cuando empezamos a integrar el patrón con eventos, la complejidad aumenta aún más. También debemos comprobar la coherencia de los datos con mucho más cuidado, y tener una gestión de consenso muy bien definida, aunque estos problemas son más bien propios de los SSDD.
Sin embargo, en aplicativos que no utilizan varios hilos separados, como por ejemplo una API de asp.net Core o una aplicación de Blazor, podemos ceñirnos al patrón y obtener muchas más ventajas que inconvenientes.
El mediador
Asociado a estos escenarios, existe otro patrón que ayuda a la implementación de CQRS de manera sencilla y aunque no siempre correcta, recordemos que CQRS solo segrega las responsabilidades, y podemos aplicarlo de muchas maneras, con un mediador o sin él.
Este patrón se basa en la intermediación de un mediador entre un servicio que intenta consumir recursos y los manejadores encargados de servir, desacoplando la interacción directa entre ambos, proporcionando una interfaz de separación entre por ejemplo una interfaz web y las querys/commands de una aplicación.
La interfaz no sabe nada de la aplicación, solo sabe que, enviando una solicitud mediante el mediador, obtiene unos resultados esperados, consiguiendo un desacople funcional estupendo que nos puede dar cintura para retrasar lo máximo posible temas banales de arquitectura del software como la interfaz.
Conclusión
La segregación de responsabilidades a mi parecer es una estructura muy potente a la hora de la lectura y la mantenibilidad del código, más allá de las ventajas (o no) de rendimiento asimétrico. El implementar esta segregación nos da muchísimo a un coste reducido(no son muchas más líneas), pudiendo tener un código mantenible y legible.
Utilizar un mediador (como MediatR) también puede ayudar desacoplando las capas mediante la inversión de dependencias, pero ojo, podemos implementar CQRS sin ninguna librería, todo dependerá del proyecto y del funcionamiento del sistema.
