Empujar o tirar, ¿Cuál es mejor?
Cuando hablamos de arquitecturas cliente-servidor, existen 2 formas de comunicación de los clientes con los servidores: PULL y PUSH. Sus nombres hacen referencia a la manera en que la información es requerida por parte del sistema.
El modelo PULL
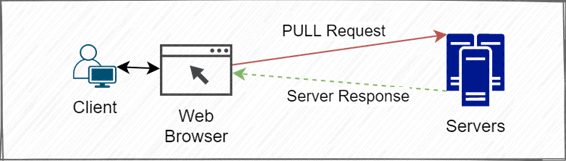
En el modelo denominado PULL, el cliente es quien inicia la comunicación con el servidor, es decir, es el cliente quien requiere la información y el servidor contesta. Los clientes son quienes consultan los datos cuando los necesitan, el servidor se limita a suministrarlos en el momento y en ningún otro.
Los servidores en este tipo de arquitectura están a la espera de que los clientes necesiten sus datos actualizados, estas peticiones pueden ser requeridas por un usuario o estar programadas en un cliente, que actualiza la información en intervalos de tiempo predefinidos.
Los receptores de la comunicación puede analizar (y generalmente lo hace) la reputación del servidor, y también gestiona el interés del contenido emitido, puede contemplarlo o descartarlo, es decir, es el cliente quien controla lo que le interesa de toda la información recibida.
Por ejemplo, podemos definir una búsqueda en un servidor como una petición PULL, el usuario introduce sus claves de búsqueda y el cliente (navegador) envía una petición PULL al servidor requiriendo información. En general este tipo de modelo de comunicación es muy utilizado en todo internet y particularmente en las solicitudes HTTP(S) de las páginas WEB.
También podemos encontrar este tipo de tecnologías en protocolos de correo electrónico como POP3 e IMAP. Ciertamente no en todos los casos (las aplicaciones propietarias de GMAIL entre otras, sí que utilizan técnicas de PUSH con SMTP), pero generalmente, en clientes de terceros, es este el que comprueba en los servidores si hay correos nuevos y descarga toda la información mediante comunicación PULL.
El modelo PUSH
En las comunicaciones PUSH, se invierten los papeles con respecto a PULL, en este escenario, es el servidor quien inicia la comunicación.
Los servidores deciden que tienen mensajes que interesan a los clientes o los nodos del sistema. De esta manera el sistema enviará el mensaje con el contenido identificado como de interés sin que realmente los clientes hayan solicitado nada.
Este tipo de arquitectura descarga a los servidores de peticiones innecesarias, ya que es este quien decide cuando hay algo que deba comunicar, y no es interrumpido constantemente con peticiones que no son necesarias (y lo protege de ataques de denegación de servicio).
Como ejemplo de comunicaciones PUSH podemos poner el servicio de mensajería por excelencia, WhatsApp utiliza notificaciones PUSH en los terminales móviles cuando recibe mensajes que debe comunicar a sus destinatarios. El terminal es informado por parte de los servidores de que le ha llegado un mensaje que debe comunicar al usuario configurado.
Un sistema bancario de distribución de listas negras de tarjetas podría ser otro buen ejemplo de comunicación PUSH. Son los servidores quienes informan a los nodos de que tienen una lista actualizada de números en lista negra, y esta es distribuida sin ser solicitada.
La utilización PUSH o PULL depende de un gran número de factores, generalmente relacionados con la funcionalidad y cometido del sistema o los aplicativos, aunque podemos discernir ciertos patrones genéricos que podemos aplicar en diferentes situaciones.
¿Por qué PULL?
Utilizaremos PULL cuando queramos tener cierto control en el lado del cliente, o cuando sea importante que sea este el que decida o necesite una interacción con el servidor (ya sea una búsqueda, un dato, o algún tipo de servicio que el cliente necesite). También hay que valorar que este tipo de comunicación es más sencilla y tiene menos implicaciones a nivel de sistema.
No utilizaremos PULL cuando el consumo de recursos por parte del cliente sea importante, este tipo de modelos generalmente cargan a los clientes con procesos o interacciones que pueden interferir en el rendimiento de estos.
Además, tendremos que asumir que la información mostrada por los clientes puede estar desfasada, por tanto si la inmediatez o si el “Tiempo real” es importante, el método PULL no es una buena decisión.
¿Por qué PUSH?
En contrapartida Utilizando PUSH, los clientes se liberan de tener que ejecutar peticiones de datos (programados o manuales), simplemente espera a que los servidores envíen información importante para ellos, esto descarga el lado del cliente en cuanto a rendimiento se refiere.
Como añadido la carga del servidor es menor, ya que no atiende peticiones innecesarias si no tiene datos nuevos. La validez de la información también es una ventaja en este tipo de comunicación, todos los nodos disponen de la misma información, ya que el servidor se encarga de esto eliminando las diferentes versiones de datos en los clientes. Aplicativos de tiempo real, o que necesitan una coordinación especifica serian candidatos a métodos de comunicación PUSH como norma general.